HotSpot JVM源码分析 - 方法调用与解释执行(5):由movl看汇编器如何生成机器码
本系列文章基于 OpenJDK 9,聚焦 x86 平台。
本文以 movl 为例,分析 HotSpot JVM 如何使用汇编器生成机器码。
背景
类似 invokevirtual 的字节码指令,在 解析 阶段将 符号引用 解析成 直接引用 后,解析结果会放在 常量池缓存(ConstantPoolCache),后续调用直接使用缓存条目,而不用再次解析。
常量池缓存结构如下(openjdk\hotspot\src\share\vm\oops\cpCache.hpp):
1 | class ConstantPoolCache: public MetaspaceObj { |
这是常量池缓存字段,紧跟其后的是 常量池缓存条目 (ConstantPoolCacheEntry)数组,_length 即数组的大小。
常量池缓存条目结构如下(openjdk\hotspot\src\share\vm\oops\cpCache.hpp):
1 | class ConstantPoolCacheEntry VALUE_OBJ_CLASS_SPEC { |
其有 4 个字段,具体意义我们在后面文章中再解释,本文关注 _indices 字段,该字段中包含字节码指令等信息:
// _indices = invoke code for f1 (b1 section), invoke code for f2 (b2 section), original constant pool index
现在看一段源码(openjdk\hotspot\src\cpu\x86\vm\interp_masm_x86.cpp):
1 | void InterpreterMacroAssembler::get_cache_and_index_and_bytecode_at_bcp(Register cache, |
这段代码由解释器调用,用来生成 “获取 常量池缓存条目” 的机器码。
这里一定要区分好 解释器 和 运行时 两种环境,代码由 解释器 调用,作用是生成供 运行时 执行的机器码。
寄存器 cache, index, bytecode 分别用来存放 常量池缓存 首地址,常量池缓存条目 的数组索引和字节码指令。
首先调用 get_cache_and_index_at_bcp 方法获取 cache 和 index。
之后下面这行代码就用来获取 常量池缓存条目 的 _indices 字段数据,将其放在 bytecode 寄存器。再次强调,不是 解释器 执行时如此,而是生成的机器码在 运行时 如此。
1 | movl(bytecode, Address(cache, index, Address::times_ptr, ConstantPoolCache::base_offset() + ConstantPoolCacheEntry::indices_offset())) |
正题
看一下 movl 的源码(openjdk\hotspot\src\cpu\x86\vm\assembler_x86.cpp):
1 | void Assembler::movl(Register dst, Address src) { |
第 2 行生成指令前缀,第 3 行生成单字节指令,第 4 行生成操作数;无视指令前缀,我们只关注指令和操作数。
这里展开,就牵扯到 Intel x86指令集 的内容了。
先看指令格式图:
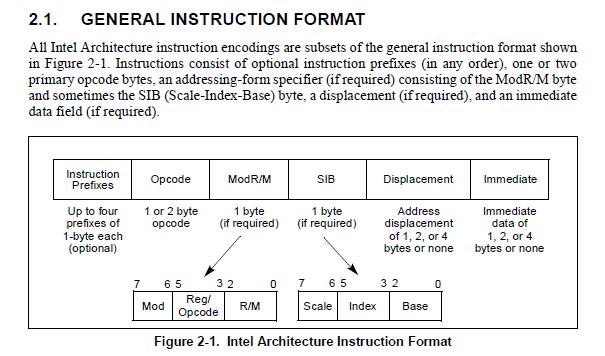
上面是指令格式,下面是两个操作数的位含义。
继续看 movl 源码。
参数类型 Register 是寄存器,Address 顾名思义是地址,结构如下:
1 | class Address VALUE_OBJ_CLASS_SPEC { |
封装了不同寻址模式所需的参数,对照一下上面指令集格式图,各个字段的意义就很清楚了,下面我们还是详细说一下。
movl 第3行 emit_int8((unsigned char)0x8B) 写入的 opcode 是 0x8B ,对应 mov 指令,参考下图:
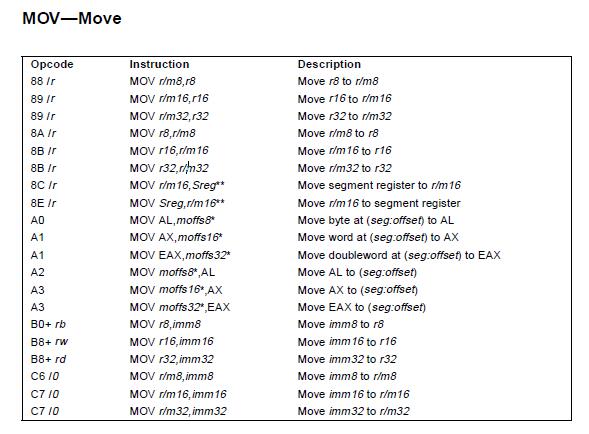
32位模式下,其格式是这样的:
8B /r MOV r32,r/m32 Move r/m32 to r32
该指令有两个操作数,第 1 个操作数是目的寄存器,第 2 个操作数是源寄存器或地址,指令作用是将源寄存器或地址的数据写到目的寄存器。
movl 第 4 行 emit_operand(dst, src) 即生成两个操作数。
源码如下:
1 | void Assembler::emit_operand(Register reg, Address adr, |
又调用了另外一个 emit_operand, 并把 Address 封装的字段作用参数传递过去。
1 | void Assembler::emit_operand(Register reg, Register base, Register index, |
代码很长,这里只截取了我们这次涉及到的部分。
结合前面源码,因为 4 个重要参数 cache, index, scale, disp 都有值,disp 是 常量池缓存 的size + 常量池缓存条目 字段 _indices 的偏移, 逻辑会走到 else if 块。
单摘出来:
1 | // [base + index*scale + imm8] |
注释已经把操作数位意义和寻址方式都描述出来了,下面解释一下为什么是这样的。
先看第 1 个操作数,为 0x44 | regenc。
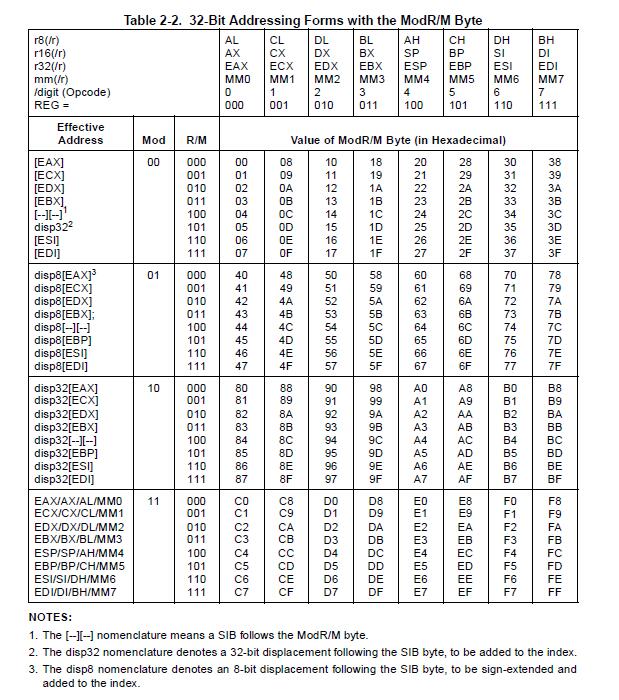
回头看一下x86指令集指令格式图,可知,第一个操作数为 ModR/M 字节,其形式如下:
0x44 二进制形式为 01 000 100,高 2 位 01 是 Mod,中 3 位 000 是 Reg/Opcode,低 3 位 100 是 R/M。
图最上面那一栏,中3位 000 或 上
regenc就等于regenc,也就是根据regenc的值选择对应 目的寄存器。高 2 位 Mod 是 01,查上表可知,所在栏均为 disp8 ,低 3 位 R/M 是 100,查上表可知,对应 disp8[–][–]。看NOTES,[–][–] 表示后续跟着一个 SIB,即第 2 个操作数是 SIB;disp8 表示有第 3 个1个字节的操作数,表示偏移。
整体寻址模式为
BASE + INDEX * SCALE + DISP。
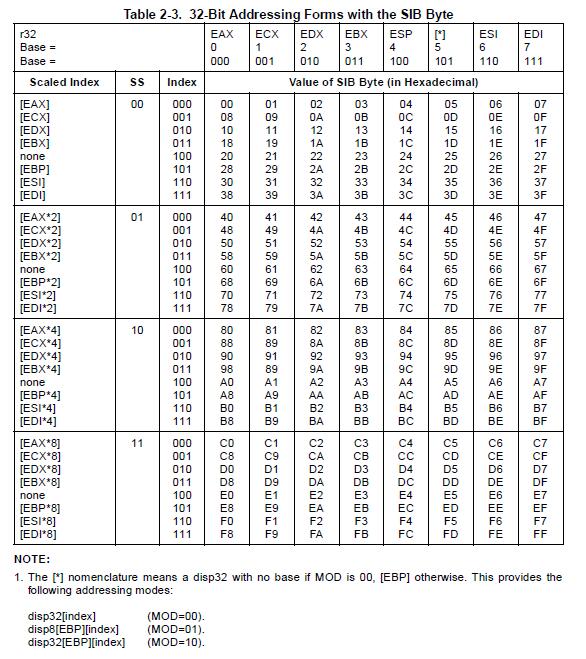
再看第 2 个操作数,为 scale << 6 | indexenc | baseenc。
由第 1 个操作数得知,第 2 个操作数是 SIB 字节,其形式如下:
图最上面那一栏,根据
baseenc的值选择 base寄存器。前面传入的
scale参数为Address::times_ptr,值为 3,二进制为 11 ,对应上表 SS,即最后一栏。index意为选择哪个 index寄存器 及操作,结果就是index * 8。
再看第 3 个参数,为 disp & 0xFF。
由第 1 个操作数得知,第 3 个操作数是 disp。
综上,emit 3 个操作数后,机器码最终为 0x8B [01 reg 100] [11 index base] [disp],表示为 mov reg [base + index * 8 + disp],意义是从地址 [base + index * 8 + disp] 取出数值,放到 reg 寄存器,即将 常量池缓存 中的 常量池缓存条目 数组中索引index 处的缓存条目 _indices 字段的值拷贝到 bytecode 寄存器。
话外
回到我们最初的代码:
1 | movl(bytecode, Address(cache, index, Address::times_ptr, ConstantPoolCache::base_offset() + ConstantPoolCacheEntry::indices_offset())) |
Address 的构造参数 cache 是常量池缓存首地址,对应 base;index 是常量池缓存条目数组索引,对应 index; ConstantPoolCache::base_offset() + ConstantPoolCacheEntry::indices_offset() 是 常量池缓存 头部大小 + 常量池缓存条目 字段 _indices 的偏移,对应 disp。
按照我们上面的公式,任意 index 缓存条目字段 indices 的地址为:
1 | base + index * 8 + ConstantPoolCache::base_offset() + ConstantPoolCacheEntry::indices_offset() |
再看下前面 ConstantPoolCacheEntry 的结构定义,肯定会觉得不对呀,一个缓存条目有 4 个字段,大小为 32,怎么这里才 * 8? 应该 * 32 才对。
其实,此 index 已非彼 index,原因就在 get_cache_and_index_at_bcp 方法里:
1 | void InterpreterMacroAssembler::get_cache_and_index_at_bcp(Register cache, |
可以看到,调用 get_cache_index_at_bcp 获取到 index,此时确实是缓存条目数组索引,但后面因为缓存条目大小为 4 * wordSize,wordSize 等同一个指针size,等同我们公式里的 8,所以执行了 shll(index, 2),左移 2 位即 * 4,此后 index 已经等于 缓存条目数组索引 * 4 了。